Dei uma quietada essa semana com as features do Forked Reality. Até fiquei tentando fazer umas coisas novas, mas menos focadas no produto. Como, por exemplo, uma automação pra me ajudar a bolar uns tweets sobre as novidades nos experimentos e tudo mais. Mas não deu muito certo porque uma das ferramentas que preciso não tá funcionando no Claude. 🙄
"I am its smallest paramedic."
— Forked Reality (@forked_reality) April 15, 2026
Pidge placed the second token today. Two conduits lit. A pulse rose through the rock. In the river, a ribbon of light surfaced, watched, and dove.
Day 10. The city has a heartbeat again.https://t.co/TFeLUEa7a0 pic.twitter.com/5gv4IqScjr
Porém, uma outra ansiedade começou a bater essa semana: tá chegando o prazo de declarar o Imposto de Renda. Eu detesto essa época, até porque minha declaração tem anos que virou uma zona, desde que comecei a diversificar demais meus investimentos. Não tenho contador (e nem pretendo contratar um) e é um inferno quando chega essa época.
“diversifiquem investimentos, é muito melhor”
— mario (@meriw__) April 19, 2023
eu fazendo meu imposto de renda depois: pic.twitter.com/ZQxLfeJ6ui
Tem quase 10 anos que eu não só faço a minha própria como ainda acabo ajudando a família a fazer também. Meu processo é sempre o mesmo:
- Baixo todos os informes de rendimento e coloco em uma pasta todos os PDFs
- Vou preenchendo um informe de cada vez, uma ficha de cada vez, deixando “Bens e Direitos” por último
- Vou revisando linha por linha de cada informe e anotando no PDF o que já revisei
- Choro quando vejo que vou ter que pagar mais imposto
ok, fiz 95% do meu imposto de renda, agora posso enrolar com calma até o último dia
— mario (@meriw__) April 12, 2023
Meu processo é simples, mas é bem chato pela quantidade de itens que tem. Ano passado já tinha me vindo essa ideia de automatizar isso:
IA, faça meu imposto de renda
— mario (@meriw__) March 19, 2025
Esse ano resolvi brincar um pouco com isso. Eu sei que ainda não dá pra confiar numa IA pra fazer um documento inteiro que, se eu estiver errado, posso ir pra cadeia. Mas o processo tem como ser mais fácil e 90% do meu processo sempre foi uma tarefa repetitiva de copia e cola.
Juntando os dados necessários
Comecei usando uma ferramenta pra converter todos meus PDFs de informes de rendimento pra Markdown. Afinal é o formato que LLMs entendem, e ficar lendo PDFs em cada turno parecia um grande desperdício de tokens.
Usei o MinerU, que é uma ferramenta open-source e local que faz esse parsing de PDFs. Ótimo, tudo convertido e nenhum token gasto.
Ainda assim, vários arquivos com formatos parecidos mas ainda não suficientemente estruturados. Pensei então em recorrer à LLM de novo pra consolidar tudo num relatório só. Daí não teve jeito, tive que apelar ao Claude. O problema? Enviar todas minhas informações de renda pra Anthropic processar na nuvem. Não recomendo – mas tudo bem, resolvi relevar isso dessa vez em nome da preguiça ciência. Até tenho alguns modelos locais com o Ollama mas não são tão capazes assim.
O resultado one-shot pelo Claude foi suficientemente bom - dados organizados por ficha e por instituição. Tudo que eu precisava copiar em um lugar só, estruturado. Sem PDFs que não deixam selecionar o texto, que copiam valores errados, sem ficar abrindo 10 arquivos ao mesmo tempo.
Diminuindo a fricção
Agora, a parte visual: criar uma visualização fácil pra isso. Criei um frontend que lê esses dados e permite filtrar de diferentes maneiras, clicar nos valores pra copiar pra área de trabalho (ex: CNPJs, nomes, valores) e colar facilmente no IRPF 2026.
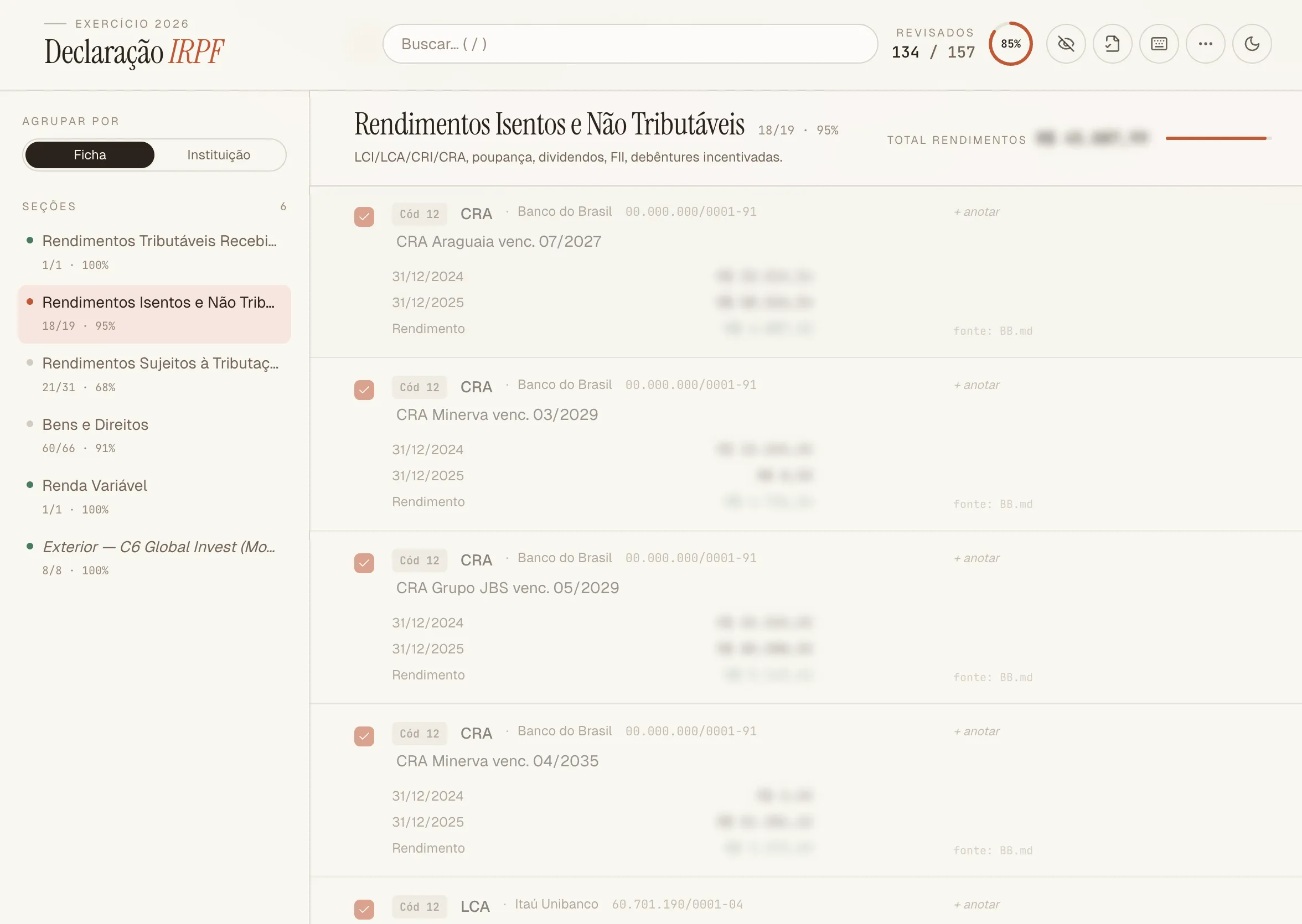
A melhor feature pra mim é uma que existe na versão web do IRPF mas não no aplicativo: um botão de “marcar como revisado”, pra eu saber que já inseri aquilo e conferi os valores. Bato o olho e vejo quantos % dos itens já revisei, e o quão perto eu tô de terminar a declaração. Sensação de progresso!
Até agora, já fiz 85% da minha declaração. Já me sinto bem mais confiante de que não esqueci nada dessa vez.
Revisão dos dados
A cereja do bolo eu ainda não descobri bem como fazer. Até agora tudo ainda é um processo manual, apenas mais bonitinho e menos propenso ao erro. Mas o que faltaria pra IA fazer, de fato, essa parte de inserir tudo mesmo? Ou pelo menos de fazer uma revisão inicial dos dados? Vamos focar nessa segunda parte, que parece mais fácil.
Não precisei fuçar muito pra descobrir que o app do IRPF salva todas as informações da declaração num XML na minha pasta de documentos (em ~/Documents/ProgramasRFB/IRPF2026/aplicacao/dados/<CPF>/<CPF>-0000000000.xml). Tem os arquivos de exportação (.DBK) que o próprio programa exporta, mas achei muito caóticos de entender, enquanto o XML pelo menos já é mais estruturado – ainda que não documentado. Ao invés de precisar exportar do programa, qualquer alteração é refletida no XML ao salvar. Usando o Opus, consegui documentar o schema desse XML gerado. Trabalho fácil pra LLM. Devo colocar isso num GitHub qualquer hora.
O próximo passo é usar esses dados – do que já está dentro da declaração – para bater com o que nós mesmo geramos, e destacar quais itens estão divergindo ou faltando. Parece simples, mas como os dados nem sempre estão descritos da mesma forma, ainda não avancei muito.
O problema: na minha declaração, alguns itens acabo agrupando na hora de colocar em Bens e Direitos. Por exemplo, 3 CDBs do mesmo emissor viram uma só linha “Banco X - CDBs” nessa seção. Outros itens vêm com nomes altamente abreviados nos informes e na declaração estão escritos de outra forma. Trabalho que uma LLM seria capaz de interpretar, porém bem mais difícil ter um algoritmo determinístico que é capaz de entender todas essas sutilezas. Mas aí já teria que entrar a LLM de novo aí mexendo nos dados e esse simples visualizador precisaria de uma API key pra rodar também.
E assim, quem sabe, fazer o IRPF não se torna algo menos assustador pro futuro. Ou, num mundo ideal, nem precisar disso – a declaração pré-preenchida cada ano mais vem mais completa e precisando de corrigir menos coisas.